Learning in neural networks is normally thought of as modifications of synaptic strengths by for example back-propagation or Hebbian learning. In (Yamauchi and Beer, 1994) however, the authors described the abilities of fixed synapse continuous time recurrent neural networks (CTRNNs) to display reinforcement learning-like properties by exploiting internal network dynamics. The task studied was generation and learning of short bit sequences. In this project we apply the same approach to a tasks where robots has to navigate in small environments requiring them to carry on information between successive trials. Both neural networks with synaptic changes by Hebbian learning rules (PNNs) and neural networks with continuous-time dynamics (CTRNNs) are applied. The results challenge the common held beliefs that neural activities are responsible for behavior and synaptic changes in neural networks are responsible for learning.
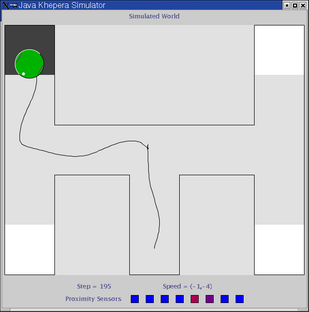
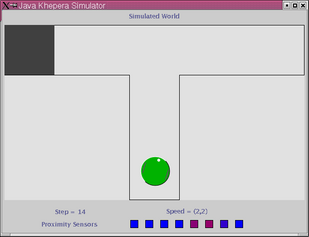
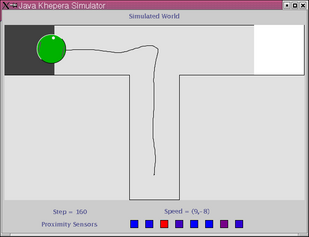
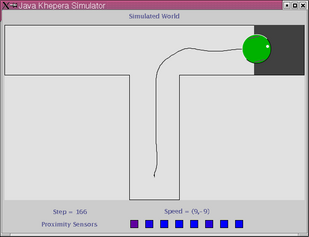
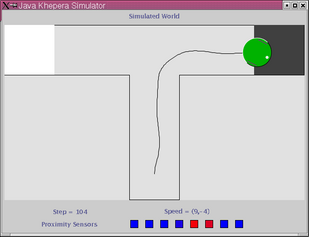
In this experiment the robot has to navigate a simple T-maze (see above). The experiment is carried out in a realistic simulation of the Khepera robot based on sensor sampling. Initially the robot is positioned as shown above, and the task is to find and stay on the black goal-area which can be positioned in either the left or the right arm of the maze. The position of the reward-zone stays fixed during each epoch. The robot is tested for 4 epochs of 5 trials each - two epochs with the reward-zone in each arm of the maze. The neural network controlling the robot is initialized (by setting the state of each neuron to zero) at the beginning of each epoch but not between trials within the same epoch. This means that the robot can potentially build up and store information in the dynamic state of the network between trials within the same epoch.
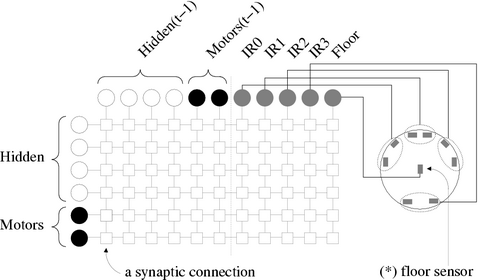
The network consists of 6 fully interconnected neurons (4 hidden + 2 motor outputs) and 5 sensory receptors. Every neuron has synaptic connections from all neurons and all sensory receptors. The receptors are configured as follows: 4 inputs from the infrared proximity sensors paired two-by-two and 1 additional input from a floor sensor pointing downwards measuring the surface brightness.
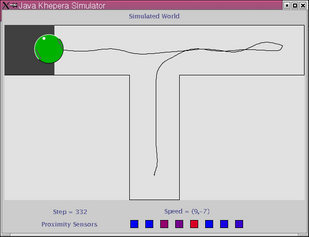
Below is shown the traces trial 1 and 2 of two epochs. In trial 1 (left column) the robot explores the environment, locates and stays on the goal area. In trial 2 (right column) the robot moves directly towards the goal area.
 |
 |
 |
 |